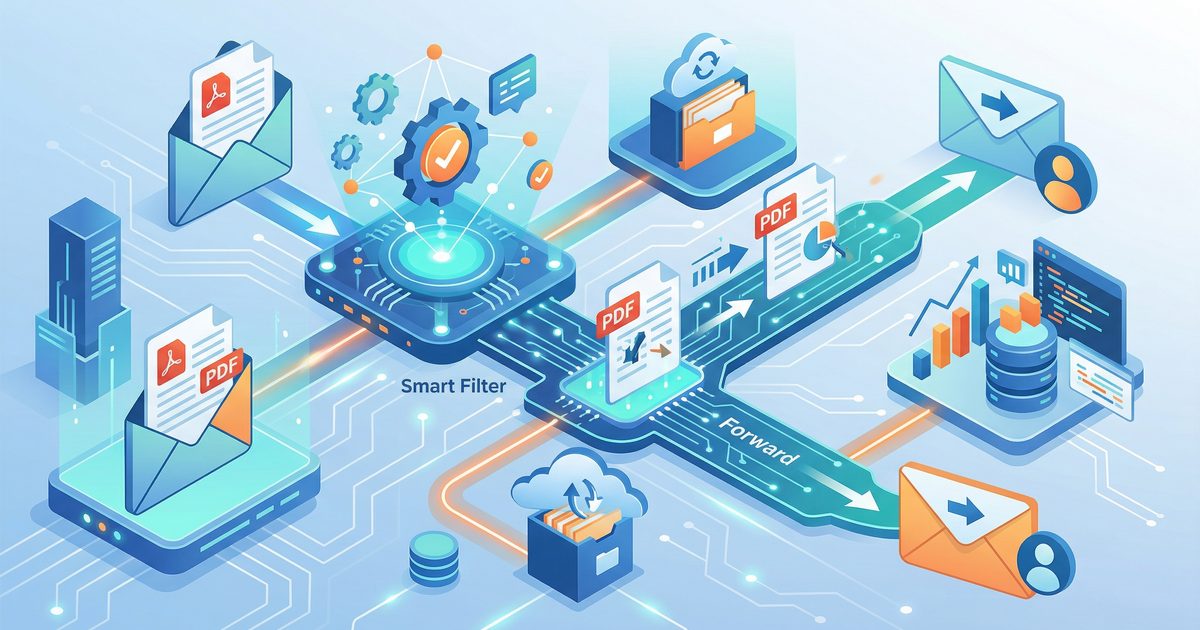
Smart Email Forward dengan PDF Attachment — Otomatis & Pintar
📎 Source:openclaw-sumopod — view on GitHub & star ⭐
📧 Smart Email Forward with PDF Data Extraction
Automate Invoice Processing with OpenClaw Sumopod
🎯 TL;DR (Too Long; Didn't Read)
What: Automatically find emails with PDF attachments, extract key data, and forward formatted summaries to your team. Time: 15 minutes setup Result: No more manual copy-paste from invoices! 🤖
┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Gmail │───▶│ Download │───▶│ Extract │───▶│ Forward │
│ Invoice │ │ PDF Attach │ │ Invoice Data│ │ Formatted │
│ Email │ │ to /tmp │ │ (amount, #) │ │ Email │
└─────────────┘ └─────────────┘ └─────────────┘ └─────────────┘
💡 Why Use This?
Real-World Scenario
Before (Manual Hell): 😫
1. Open Gmail
2. Find invoice email from vendor
3. Download PDF attachment
4. Open PDF, squint at numbers
5. Copy invoice number
6. Copy total amount
7. Copy due date
8. Open new email
9. Type everything manually
10. Send to accounting@company.com
11. Repeat 50x per day... 💀
After (Automation Magic): ✨
1. Run workflow once
2. All invoices processed automatically
3. Accounting gets clean data
4. You get coffee ☕
Perfect for:
- 📊 Invoice processing
- 📑 Receipt collection
- 🧾 Expense report automation
- 📋 Purchase order tracking
🗺️ Visual Workflow Map
┌─────────────────────────────────────┐
│ WORKFLOW OVERVIEW │
└─────────────────────────────────────┘
│
▼
┌───────────────────────────────────────────────────────────────┐
│ STEP 1: SEARCH │
│ ┌─────────────┐ │
│ │ Gmail Query │──▶ "from:vendor@acme.com has:attachment" │
│ └─────────────┘ │
└───────────────────────────────────────────────────────────────┘
│
▼
┌───────────────────────────────────────────────────────────────┐
│ STEP 2: DOWNLOAD │
│ ┌─────────────┐ ┌─────────────┐ │
│ │ Get Email │──▶ │ Save PDF │ │
│ │ Attachments │ │ to /tmp/ │ │
│ └─────────────┘ └─────────────┘ │
└───────────────────────────────────────────────────────────────┘
│
▼
┌───────────────────────────────────────────────────────────────┐
│ STEP 3: EXTRACT │
│ ┌─────────────┐ ┌─────────────────────┐ │
│ │ Parse PDF │──▶ │ Extract: │ │
│ │ Text/Tables │ │ • Invoice Number │ │
│ └─────────────┘ │ • Total Amount │ │
│ │ • Due Date │ │
│ │ • Vendor Name │ │
│ └─────────────────────┘ │
└───────────────────────────────────────────────────────────────┘
│
▼
┌───────────────────────────────────────────────────────────────┐
│ STEP 4: FORMAT & FORWARD │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ Build Clean │──▶ │ Format as │──▶ │ Send to │ │
│ │ Data Object │ │ HTML/Markdown│ │ Recipient │ │
│ └─────────────┘ └─────────────┘ └─────────────┘ │
└───────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────┐
│ ☕ COFFEE TIME! │
└─────────────────────┘
🛠️ Prerequisites
Before we start, make sure you have:
Install Required Tools
# Option 1: Install pdftotext (recommended, faster)
sudo apt-get install poppler-utils
# Option 2: Install Python PDF library
pip install PyPDF2 pdfplumber
🚀 Step-by-Step Implementation
Step 1: Create the Workflow Directory
mkdir -p ~/workflows/email-pdf-processor
cd ~/workflows/email-pdf-processor
Step 2: Create the Main Script
Create file: process_invoices.py
#!/usr/bin/env python3
"""
📧 Smart Email Forward with PDF Data Extraction
Automates invoice processing from Gmail
"""
import os
import re
import json
import tempfile
from datetime import datetime
from pathlib import Path
# ============================================================
# CONFIGURATION - Edit these for your needs
# ============================================================
CONFIG = {
# Gmail search query - customize this!
"search_query": "from:vendor@example.com has:attachment filename:pdf newer_than:1d",
# Where to forward extracted data
"forward_to": "accounting@acmecorp.com",
# Email subject prefix
"subject_prefix": "[AUTO-INVOICE]",
# PDF download directory (auto-cleanup)
"download_dir": "/tmp/invoice_pdfs",
# Debug mode (prints extra info)
"debug": True
}
# ============================================================
# STEP 1: Search Gmail for Invoice Emails
# ============================================================
def search_emails(query):
"""
🔍 Search Gmail using gog CLI
Returns list of emails matching query
"""
import subprocess
print(f"🔍 Searching Gmail: {query}")
cmd = ["gog", "gmail", "search", query, "--max=10", "--json"]
try:
result = subprocess.run(cmd, capture_output=True, text=True)
emails = json.loads(result.stdout)
print(f"✅ Found {len(emails)} email(s)")
return emails
except Exception as e:
print(f"❌ Search failed: {e}")
return []
# ============================================================
# STEP 2: Download PDF Attachments
# ============================================================
def download_attachments(email_id, download_dir):
"""
📥 Download all PDF attachments from an email
Returns list of downloaded file paths
"""
import subprocess
import shutil
os.makedirs(download_dir, exist_ok=True)
downloaded = []
# Get email details
cmd = ["gog", "gmail", "get", email_id, "--include-attachments", "--save-to", download_dir]
try:
result = subprocess.run(cmd, capture_output=True, text=True)
# Find PDF files in download directory
for file in os.listdir(download_dir):
if file.lower().endswith('.pdf'):
full_path = os.path.join(download_dir, file)
downloaded.append(full_path)
print(f" 📄 Downloaded: {file}")
return downloaded
except Exception as e:
print(f"❌ Download failed: {e}")
return []
# ============================================================
# STEP 3: Extract Data from PDF
# ============================================================
def extract_pdf_data(pdf_path):
"""
📊 Extract invoice data from PDF
Uses regex patterns to find common invoice fields
"""
import subprocess
print(f" 🔍 Extracting: {os.path.basename(pdf_path)}")
# Try pdftotext first (most reliable)
try:
result = subprocess.run(
["pdftotext", "-layout", pdf_path, "-"],
capture_output=True,
text=True,
timeout=30
)
text = result.stdout
except:
# Fallback: Try PyPDF2
try:
import PyPDF2
with open(pdf_path, 'rb') as f:
reader = PyPDF2.PdfReader(f)
text = ""
for page in reader.pages:
text += page.extract_text() or ""
except Exception as e:
print(f" ⚠️ Could not extract text: {e}")
return None
# Clean up text
text = text.replace('\n', ' ').replace('\r', ' ')
text = ' '.join(text.split()) # Remove extra spaces
# ========================================================
# PATTERN MATCHING - Customize these for your invoices!
# ========================================================
data = {
"filename": os.path.basename(pdf_path),
"extracted_text_snippet": text[:500] + "..." if len(text) > 500 else text,
"fields": {}
}
# Pattern 1: Invoice Number (various formats)
invoice_patterns = [
r'[Ii]nvoice\s*[Nn]o\.?\s*:?\s*([A-Z0-9\-]+)',
r'[Ii]nvoice\s*#\s*:?\s*([A-Z0-9\-]+)',
r'[Nn]o\.?\s*[Ff]aktur\s*:?\s*([A-Z0-9\-]+)',
r'[Ff]aktur\s*:?\s*([A-Z0-9\-]+)'
]
for pattern in invoice_patterns:
match = re.search(pattern, text)
if match:
data["fields"]["invoice_number"] = match.group(1).strip()
break
# Pattern 2: Total Amount (various formats)
amount_patterns = [
r'[Tt]otal\s*:?\s*Rp\.?\s*([\d.,]+)',
r'[Tt]otal\s+[Aa]mount\s*:?\s*Rp\.?\s*([\d.,]+)',
r'[Jj]umlah\s*:?\s*Rp\.?\s*([\d.,]+)',
r'[Gg]rand\s+[Tt]otal\s*:?\s*Rp\.?\s*([\d.,]+)',
r'[Tt]otal\s+[Pp]embayaran\s*:?\s*Rp\.?\s*([\d.,]+)'
]
for pattern in amount_patterns:
match = re.search(pattern, text)
if match:
amount_str = match.group(1).replace('.', '').replace(',', '.')
data["fields"]["total_amount"] = f"Rp {amount_str}"
break
# Pattern 3: Due Date
date_patterns = [
r'[Dd]ue\s+[Dd]ate\s*:?\s*(\d{1,2}[/-]\d{1,2}[/-]\d{2,4})',
r'[Tt]anggal\s+[Jj]atuh\s+[Tt]empo\s*:?\s*(\d{1,2}[/-]\d{1,2}[/-]\d{2,4})',
r'[Jj]atuh\s+[Tt]empo\s*:?\s*(\d{1,2}[/-]\d{1,2}[/-]\d{2,4})'
]
for pattern in date_patterns:
match = re.search(pattern, text)
if match:
data["fields"]["due_date"] = match.group(1)
break
# Pattern 4: Vendor/Company Name
vendor_patterns = [
r'[Ff]rom\s*:?\s*([A-Z][A-Za-z\s]+(?:PT|CV|Ltd|Inc)?\.?)',
r'[Dd]ari\s*:?\s*([A-Z][A-Za-z\s]+(?:PT|CV)?\.?)',
r'([A-Z][A-Za-z\s]+(?:PT|CV)\s+[A-Za-z\s]+)'
]
for pattern in vendor_patterns:
match = re.search(pattern, text)
if match:
data["fields"]["vendor"] = match.group(1).strip()
break
# Pattern 5: Description/Items (first line)
desc_match = re.search(r'[Dd]escription\s*:?\s*([^:]+?)(?=[Qq]ty|[Uu]nit|[Pp]rice)', text)
if desc_match:
data["fields"]["description"] = desc_match.group(1).strip()[:100]
print(f" ✅ Extracted {len(data['fields'])} fields")
return data
# ============================================================
# STEP 4: Format and Forward Email
# ============================================================
def format_and_forward(extracted_data, original_email):
"""
📤 Format extracted data and send forward email
"""
import subprocess
# Build HTML email body
html_body = f"""
<html>
<head>
<style>
body {{ font-family: Arial, sans-serif; line-height: 1.6; }}
.header {{ background: #4CAF50; color: white; padding: 20px; }}
.content {{ padding: 20px; }}
.invoice-card {{ border: 1px solid #ddd; border-radius: 8px; margin: 15px 0; padding: 15px; }}
.field {{ margin: 8px 0; }}
.label {{ font-weight: bold; color: #555; display: inline-block; width: 150px; }}
.value {{ color: #333; }}
.amount {{ font-size: 1.2em; color: #4CAF50; font-weight: bold; }}
.footer {{ background: #f5f5f5; padding: 15px; font-size: 0.9em; color: #666; }}
</style>
</head>
<body>
<div class="header">
<h2>📧 Automated Invoice Processing</h2>
<p>Extracted from: {original_email.get('subject', 'Unknown')}</p>
</div>
<div class="content">
"""
# Add each invoice
for invoice in extracted_data:
fields = invoice.get('fields', {})
html_body += f"""
<div class="invoice-card">
<h3>📄 {invoice['filename']}</h3>
<div class="field">
<span class="label">Invoice Number:</span>
<span class="value">{fields.get('invoice_number', 'N/A')}</span>
</div>
<div class="field">
<span class="label">Vendor:</span>
<span class="value">{fields.get('vendor', 'N/A')}</span>
</div>
<div class="field">
<span class="label">Total Amount:</span>
<span class="amount">{fields.get('total_amount', 'N/A')}</span>
</div>
<div class="field">
<span class="label">Due Date:</span>
<span class="value">{fields.get('due_date', 'N/A')}</span>
</div>
<div class="field">
<span class="label">Description:</span>
<span class="value">{fields.get('description', 'N/A')}</span>
</div>
</div>
"""
html_body += f"""
</div>
<div class="footer">
<p>⏰ Processed at: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}</p>
<p>🤖 Automated by OpenClaw Sumopod</p>
</div>
</body>
</html>
"""
# Build plain text version
text_body = f"""
AUTOMATED INVOICE PROCESSING
============================
Extracted from: {original_email.get('subject', 'Unknown')}
INVOICE DETAILS:
"""
for invoice in extracted_data:
fields = invoice.get('fields', {})
text_body += f"""
---
File: {invoice['filename']}
Invoice Number: {fields.get('invoice_number', 'N/A')}
Vendor: {fields.get('vendor', 'N/A')}
Total Amount: {fields.get('total_amount', 'N/A')}
Due Date: {fields.get('due_date', 'N/A')}
Description: {fields.get('description', 'N/A')}
"""
text_body += f"""
---
Processed at: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}
Automated by OpenClaw Sumopod
"""
# Send email using gog
subject = f"{CONFIG['subject_prefix']} Invoice Data Extraction"
print(f"\n📤 Forwarding to: {CONFIG['forward_to']}")
# Save HTML to temp file for attachment
with tempfile.NamedTemporaryFile(mode='w', suffix='.html', delete=False) as f:
f.write(html_body)
html_file = f.name
try:
cmd = [
"gog", "gmail", "send",
"--to", CONFIG['forward_to'],
"--subject", subject,
"--body", text_body,
"--html-file", html_file
]
result = subprocess.run(cmd, capture_output=True, text=True)
if result.returncode == 0:
print("✅ Email forwarded successfully!")
return True
else:
print(f"❌ Failed to send: {result.stderr}")
return False
finally:
os.unlink(html_file)
# ============================================================
# MAIN WORKFLOW
# ============================================================
def main():
"""
🚀 Main execution flow
"""
print("=" * 60)
print("📧 Smart Email Forward with PDF Data Extraction")
print("=" * 60)
print()
# Step 1: Search
emails = search_emails(CONFIG["search_query"])
if not emails:
print("📭 No emails found matching criteria")
return
# Process each email
for email in emails:
print(f"\n{'─' * 50}")
print(f"📨 Processing: {email.get('subject', 'No Subject')}")
print(f" From: {email.get('from', 'Unknown')}")
print(f" ID: {email.get('id', 'N/A')}")
# Step 2: Download
download_dir = os.path.join(CONFIG["download_dir"], email.get('id', 'unknown'))
pdf_files = download_attachments(email.get('id'), download_dir)
if not pdf_files:
print(" ⚠️ No PDF attachments found")
continue
# Step 3: Extract
extracted_data = []
for pdf_file in pdf_files:
data = extract_pdf_data(pdf_file)
if data:
extracted_data.append(data)
if not extracted_data:
print(" ⚠️ Could not extract data from any PDF")
continue
# Step 4: Forward
format_and_forward(extracted_data, email)
# Cleanup
import shutil
if os.path.exists(download_dir):
shutil.rmtree(download_dir)
print(f" 🧹 Cleaned up: {download_dir}")
print(f"\n{'=' * 60}")
print("✨ Processing complete!")
print("=" * 60)
if __name__ == "__main__":
main()
Step 3: Create Configuration File
Create file: config.json
{
"search_query": "from:vendor@acmecorp.com has:attachment filename:pdf newer_than:1d",
"forward_to": "accounting@acmecorp.com",
"subject_prefix": "[AUTO-INVOICE]",
"download_dir": "/tmp/invoice_pdfs",
"debug": true,
"extraction_patterns": {
"invoice_number": [
"[Ii]nvoice\\s*[Nn]o\\.?\\s*:?\\s*([A-Z0-9\\-]+)",
"[Nn]o\\.?\\s*[Ff]aktur\\s*:?\\s*([A-Z0-9\\-]+)"
],
"total_amount": [
"[Tt]otal\\s*:?\\s*Rp\\.?\\s*([\\d.,]+)",
"[Jj]umlah\\s*:?\\s*Rp\\.?\\s*([\\d.,]+)"
],
"due_date": [
"[Dd]ue\\s+[Dd]ate\\s*:?\\s*(\\d{1,2}[/-]\\d{1,2}[/-]\\d{2,4})",
"[Jj]atuh\\s+[Tt]empo\\s*:?\\s*(\\d{1,2}[/-]\\d{1,2}[/-]\\d{2,4})"
]
}
}
Step 4: Create Helper Scripts
Script 1: Test Mode (No Sending)
Create file: test_extract.py
#!/usr/bin/env python3
"""
🧪 Test PDF extraction without sending emails
Usage: python3 test_extract.py /path/to/invoice.pdf
"""
import sys
import json
import re
import subprocess
def extract_text_from_pdf(pdf_path):
"""Extract text from PDF using pdftotext"""
try:
result = subprocess.run(
["pdftotext", "-layout", pdf_path, "-"],
capture_output=True,
text=True,
timeout=30
)
return result.stdout
except Exception as e:
print(f"❌ Error: {e}")
return None
def extract_invoice_data(text):
"""Extract invoice fields from text"""
text = text.replace('\n', ' ').replace('\r', ' ')
text = ' '.join(text.split())
data = {}
# Invoice Number
patterns = [
r'[Ii]nvoice\s*[Nn]o\.?\s*:?\s*([A-Z0-9\-]+)',
r'[Ff]aktur\s*:?\s*([A-Z0-9\-]+)'
]
for p in patterns:
m = re.search(p, text)
if m:
data['invoice_number'] = m.group(1)
break
# Amount
patterns = [
r'[Tt]otal\s*:?\s*Rp\.?\s*([\d.,]+)',
r'[Jj]umlah\s*:?\s*Rp\.?\s*([\d.,]+)'
]
for p in patterns:
m = re.search(p, text)
if m:
data['total_amount'] = f"Rp {m.group(1)}"
break
# Date
patterns = [
r'[Dd]ue\s+[Dd]ate\s*:?\s*(\d{1,2}[/-]\d{1,2}[/-]\d{2,4})',
r'[Jj]atuh\s+[Tt]empo\s*:?\s*(\d{1,2}[/-]\d{1,2}[/-]\d{2,4})'
]
for p in patterns:
m = re.search(p, text)
if m:
data['due_date'] = m.group(1)
break
return data
if __name__ == "__main__":
if len(sys.argv) < 2:
print("Usage: python3 test_extract.py <pdf_file>")
sys.exit(1)
pdf_file = sys.argv[1]
print(f"🔍 Testing extraction: {pdf_file}")
print("-" * 50)
text = extract_text_from_pdf(pdf_file)
if text:
print(f"📄 Text extracted ({len(text)} chars)")
print("\n📝 First 500 characters:")
print(text[:500])
print("\n" + "-" * 50)
data = extract_invoice_data(text)
print("\n✅ Extracted Data:")
print(json.dumps(data, indent=2, ensure_ascii=False))
else:
print("❌ Failed to extract text")
Make it executable:
chmod +x test_extract.py
Script 2: Dry Run Mode
Create file: dry_run.py
#!/usr/bin/env python3
"""
🧪 Dry Run - Test workflow without sending emails
Shows what WOULD be sent
"""
import subprocess
import json
# Same search as main script
SEARCH_QUERY = "from:vendor@example.com has:attachment filename:pdf newer_than:1d"
print("🔍 DRY RUN MODE - No emails will be sent")
print("=" * 50)
# Search emails
cmd = ["gog", "gmail", "search", SEARCH_QUERY, "--max=5", "--json"]
result = subprocess.run(cmd, capture_output=True, text=True)
try:
emails = json.loads(result.stdout)
print(f"\n📧 Would process {len(emails)} email(s):\n")
for i, email in enumerate(emails, 1):
print(f"{i}. {email.get('subject', 'No Subject')}")
print(f" From: {email.get('from', 'Unknown')}")
print(f" Date: {email.get('date', 'Unknown')}")
print()
print("✅ Dry run complete. No actions taken.")
print("\nTo actually process, run: python3 process_invoices.py")
except json.JSONDecodeError:
print("❌ Error parsing Gmail response")
print(result.stderr)
🧪 Testing & Verification
Test 1: Verify PDF Extraction
# Test with a sample PDF
python3 test_extract.py /path/to/sample_invoice.pdf
Expected Output:
🔍 Testing extraction: sample_invoice.pdf
--------------------------------------------------
📄 Text extracted (2847 chars)
📝 First 500 characters:
INVOICE
From: PT Example Sejahtera
Invoice No: INV-2024-001
...
--------------------------------------------------
✅ Extracted Data:
{
"invoice_number": "INV-2024-001",
"total_amount": "Rp 15.000.000",
"due_date": "15/03/2024"
}
Test 2: Dry Run
python3 dry_run.py
Expected Output:
🔍 DRY RUN MODE - No emails will be sent
==================================================
📧 Would process 3 email(s):
1. Invoice March 2024 - PT Example Sejahtera
From: vendor@acmecorp.com
Date: 2024-03-01
2. Service Invoice #245
From: vendor@acmecorp.com
Date: 2024-03-02
✅ Dry run complete. No actions taken.
Test 3: Full Run (with test email)
# First, modify config to forward to yourself
# Edit config.json: "forward_to": "your-email@example.com"
# Then run
python3 process_invoices.py
⚠️ Troubleshooting
Common Issues & Solutions
Issue 1: pdftotext: command not found
Error:
❌ Error: [Errno 2] No such file or directory: 'pdftotext'
Solution:
# Install poppler-utils (Linux)
sudo apt-get install poppler-utils
# Or use PyPDF2 fallback
pip install PyPDF2
Issue 2: Gmail Authentication Failed
Error:
❌ Search failed: Authentication required
Solution:
# Re-authenticate with gog
gog auth login
# Or check status
gog auth status
Issue 3: No Data Extracted from PDF
Error:
✅ Extracted 0 fields
Solutions:
- Check if PDF is scanned (image-based)bash
# Install OCR tools sudo apt-get install tesseract-ocr pip install pytesseract pdf2image - Adjust regex patterns for your invoice formatpython
# Add custom pattern in process_invoices.py custom_patterns = [ r'Your\s*Pattern\s*Here\s*:?\s*([A-Z0-9]+)', ] - Debug: Print full extracted textpython
# Add this to extract_pdf_data() if CONFIG["debug"]: print(f"Full text: {text[:2000]}")
Issue 4: Permission Denied on Download Directory
Error:
❌ Download failed: [Errno 13] Permission denied
Solution:
# Create directory with proper permissions
mkdir -p /tmp/invoice_pdfs
chmod 755 /tmp/invoice_pdfs
# Or change config to use different path
# Edit config.json: "download_dir": "/home/user/invoices"
Issue 5: Email Not Sending
Error:
❌ Failed to send: Error sending email
Solutions:
- Check recipient emailbash
# Verify email format
echo "accounting@acmecorp.com" | grep -E "^a-zA-Z0-9._%+-+@a-zA-Z0-9.-+.a-zA-Z{2,}$"
2. **Test gog send manually**
```bash
gog gmail send \
--to "test@example.com" \
--subject "Test" \
--body "Hello World"
- Check rate limitsbash
# Add delay between sends import time time.sleep(2) # 2 second delay
🔧 Customization Guide
Adding Custom Extraction Fields
Edit process_invoices.py and add to the extract_pdf_data() function:
# Example: Extract PO Number
po_pattern = r'[Pp]\.?[Oo]\.?\s*[Nn]o\.?\s*:?\s*([A-Z0-9\-]+)'
match = re.search(po_pattern, text)
if match:
data["fields"]["po_number"] = match.group(1)
# Example: Extract Tax Amount
tax_pattern = r'[Pp][Pp][Nn]\s*:?\s*Rp\.?\s*([\d.,]+)'
match = re.search(tax_pattern, text)
if match:
data["fields"]["tax_amount"] = f"Rp {match.group(1)}"
Changing Email Template
Find the format_and_forward() function and modify:
# Custom subject
subject = f"🚨 URGENT: Invoice {fields.get('invoice_number')} requires payment"
# Custom body
html_body = f"""
<h1>Your Custom Template Here</h1>
<p>Invoice: {fields.get('invoice_number')}</p>
"""
Filtering by Attachment Name
Add to download_attachments():
# Only process files matching pattern
if not re.match(r'^INV-\d+\.pdf$', file, re.IGNORECASE):
print(f" ⏭️ Skipping: {file} (doesn't match pattern)")
continue
📊 Monitoring & Logging
Add Logging to Your Script
import logging
from datetime import datetime
# Setup logging
logging.basicConfig(
filename=f'invoice_processor_{datetime.now():%Y%m%d}.log',
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
# Use in code
logging.info(f"Processing email: {email_id}")
logging.warning(f"No PDF found in email: {email_id}")
logging.error(f"Failed to extract: {str(e)}")
Create Processing Report
def generate_report(processed_emails, success_count, fail_count):
report = f"""
📊 Processing Report
===================
Date: {datetime.now()}
Total Emails: {len(processed_emails)}
Successful: {success_count} ✅
Failed: {fail_count} ❌
Processed:
{chr(10).join(f" - {e}" for e in processed_emails)}
"""
return report
🎯 Quick Reference Card
┌─────────────────────────────────────────────────────────┐
│ SMART EMAIL FORWARD - CHEATSHEET │
├─────────────────────────────────────────────────────────┤
│ Install deps: sudo apt-get install poppler-utils │
│ Test extract: python3 test_extract.py invoice.pdf │
│ Dry run: python3 dry_run.py │
│ Full run: python3 process_invoices.py │
├─────────────────────────────────────────────────────────┤
│ Common gog commands: │
│ • gog gmail search "query" --json │
│ • gog gmail get EMAIL_ID --include-attachments │
│ • gog gmail send --to X --subject Y --body Z │
├─────────────────────────────────────────────────────────┤
│ Regex patterns for invoices: │
│ • INV-001: [A-Z]{2,3}-\d+ │
│ • Rp 1.000.000: Rp\.?\s*[\d.,]+ │
│ • 15/03/2024: \d{1,2}[/-]\d{1,2}[/-]\d{2,4} │
└─────────────────────────────────────────────────────────┘
✅ Checklist Before Going Live
- Test PDF extraction with sample invoices
- Verify Gmail authentication working
- Run dry_run.py to confirm email selection
- Set
forward_toto your email for testing - Test full workflow with 1-2 emails
- Review extracted data accuracy
- Update regex patterns if needed
- Set up logging
- Change
forward_toto production email - Schedule with cron or n8n
🚀 Next Steps
Schedule Automatic Runs
Add to crontab for daily processing:
# Edit crontab
crontab -e
# Add line for daily run at 9 AM
0 9 * * * cd ~/workflows/email-pdf-processor && python3 process_invoices.py >> /var/log/invoice_processor.log 2>&1
Connect to n8n Workflow
- Create new n8n workflow
- Add "Execute Command" node
- Command:
cd ~/workflows/email-pdf-processor && python3 process_invoices.py - Schedule with "Cron" trigger node
📞 Need Help?
- 💬 Check OpenClaw documentation:
openclaw --help - 🔍 Review gog CLI docs:
gog --help - 🐛 Report issues with logs and sample PDFs
Created for OpenClaw Sumopod | 🤖 Automated with love
Last updated: March 2025
← Artikel Sebelumnya
Smart Email Triage dengan AI — Inbox Zero Tanpa Sakit Kepala
Artikel Selanjutnya →
Build Service Health Dashboard — Monitor Semua Service di Satu Tempat
Baca Juga


Ada Pertanyaan? Yuk Ngobrol!
Butuh bantuan setup OpenClaw, konsultasi IT, atau mau diskusi project engineering? Book a call langsung — gratis.
Book a Call — Gratisvia Cal.com • WITA (UTC+8)
Newsletter
Subscribe to Newsletter
Artikel baru, automation notes, dan engineering insight. Clean inbox, no spam.
Dengan subscribe, kamu setuju menerima update seperlunya.