AI Content Pipeline: Dari Scraping Ide sampai Publishing Bot
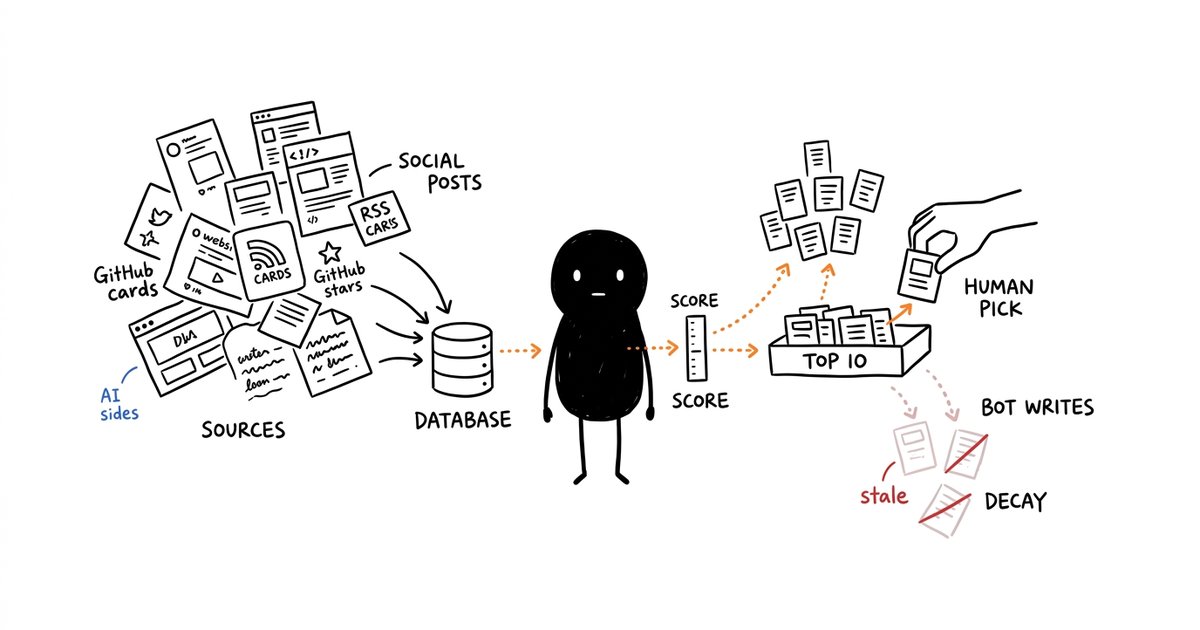
Ada satu masalah yang kelihatannya sepele, tapi makin lama makin brutal: ide konten itu berlimpah, tapi attention kita terbatas.
Setiap hari ada thread bagus di X, update menarik di GitHub, artikel teknis di blog engineering, video pendek yang menjelaskan konsep dengan cara sederhana, diskusi LinkedIn yang memancing sudut pandang baru, sampai obrolan random yang sebenarnya bisa jadi bahan tulisan. Kalau semuanya dicatat manual, kita jadi sekretaris internet. Kalau dibiarkan, banyak ide bagus hilang begitu saja.
Di sisi lain, content production modern sudah bukan sekadar “nulis artikel”. Untuk satu ide saja, output-nya bisa pecah jadi banyak bentuk: blog post, GitHub repo, newsletter, LinkedIn post, WhatsApp broadcast, short video, internal memo, atau draft proposal. Itu artinya bottleneck sebenarnya bukan cuma produksi. Bottleneck pertama adalah discovery dan curation.
Saya lebih suka melihat ini sebagai engineering problem, bukan sekadar creative problem.
Pertanyaannya bukan “bagaimana mencari ide?” Pertanyaannya adalah:
Bagaimana membangun sistem yang setiap pagi menyodorkan 10 ide terbaik, fresh, relevan, tidak repetitif, dan siap didelegasikan ke agent produksi konten?
Jawaban saya: build an AI-powered content discovery and curation pipeline.
Bukan full autopilot yang langsung scrape lalu publish ngawur. Itu resep cepat untuk bikin blog terasa seperti spam factory. Yang benar adalah semi-autonomous pipeline: mesin mengumpulkan, membersihkan, menilai, dan menyusun prioritas; manusia tetap memilih mana yang feasible, mana yang cocok dengan voice brand, dan mana yang worth shipping.
Artikel ini membahas desain lengkapnya: dari scraping media sosial dan website, database ide, scoring algorithm, morning top 10, human curation, content production delegation, sampai score decay supaya ide lama tidak muncul terus seperti sales follow-up yang nggak tahu malu.
Problem: Kita Tidak Kekurangan Ide, Kita Kekurangan Sistem
Kalau Anda developer, tech lead, atau engineering manager, kemungkinan besar Anda punya banyak sekali input harian:
- Release notes dari tool yang dipakai tim
- GitHub trending repositories
- Hacker News atau Reddit discussion
- LinkedIn posts dari founders dan engineers
- Internal Slack/Telegram conversations
- Customer questions yang berulang
- Error, incident, atau lesson learned dari project
- Paper, benchmark, framework, atau library baru
- Competitor content dan product updates
Semua itu bisa jadi konten.
Tapi tanpa sistem, yang terjadi biasanya salah satu dari tiga pola ini:
- Ide bagus lewat begitu saja karena tidak dicatat.
- Ide dicatat tapi tidak diprioritaskan, akhirnya jadi graveyard di Notion/Trello/Google Sheet.
- Ide yang sama muncul berulang, sementara ide baru tenggelam.
Manual curation juga punya masalah lain: mood. Hari ini semangat, besok sibuk, lusa lupa. Konten tidak boleh bergantung pada mood. Kalau sistem produksi konten adalah bagian dari growth engine, dia perlu rhythm, metrics, dan feedback loop.
Jadi pipeline yang ingin kita bangun punya tujuan jelas:
- Mengumpulkan ide dari banyak sumber secara otomatis
- Menyimpan semua kandidat di database
- Memberi score berdasarkan relevansi, novelty, engagement potential, dan feasibility
- Menampilkan top 10 setiap pagi
- Membiarkan manusia memilih yang paling cocok
- Mendelegasikan produksi ke bot/blog manager yang sesuai
- Menurunkan score item yang sudah pernah tampil
- Menjaga suggestion tetap fresh dan tidak repetitive
Ini bukan magic. Ini cuma good systems engineering applied to content.
High-Level Architecture
Secara konsep, pipeline ini terdiri dari delapan komponen:
- Source connectors — scraper untuk social media, RSS, website, GitHub, newsletter, dan internal notes.
- Normalizer — mengubah berbagai format input menjadi satu schema yang konsisten.
- Idea database — tempat semua content candidates disimpan.
- Enrichment agent — menambahkan summary, tags, entity, dan context.
- Scoring engine — menghitung prioritas tiap ide.
- Morning briefing — menyusun top 10 setiap pagi.
- Human curation UI — owner memilih ide yang applicable.
- Production delegation — mengirim job ke bot yang mengelola blog/channel tertentu.
Diagram sederhananya begini:
Show diagram source
flowchart LR
A[Social Media Scrapers] --> D[Normalizer]
B[Website and RSS Scrapers] --> D
C[GitHub and Internal Notes] --> D
D --> E[(Idea Database)]
E --> F[AI Enrichment Agent]
F --> G[Scoring Engine]
G --> H[Morning Top 10 Briefing]
H --> I[Human Curation]
I --> J[Content Production Bots]
J --> K[Blog, GitHub, Newsletter, Social]
H --> L[Score Decay]
L --> EKalau mau dibuat lebih production-ready, pisahkan antara ingestion, scoring, dan presentation. Jangan satu script raksasa yang melakukan semuanya. Itu cepat di awal, tapi susah dirawat.
Saya biasanya membagi sistem seperti ini:
Show diagram source
flowchart TB
subgraph Ingestion
S1[X Scraper]
S2[LinkedIn Scraper]
S3[RSS Reader]
S4[GitHub Scanner]
S5[Internal Notes]
end
subgraph Processing
N[Normalize]
E[Deduplicate]
A[AI Enrich]
Q[Quality Filter]
end
subgraph Storage
DB[(Postgres Ideas DB)]
V[(Vector Index)]
end
subgraph Decision
SC[Scoring Engine]
DEC[Score Decay]
BR[Morning Briefing]
end
subgraph Execution
HC[Human Picks]
BOT[Managing Bots]
PUB[Publish Channels]
end
S1 --> N
S2 --> N
S3 --> N
S4 --> N
S5 --> N
N --> E --> A --> Q --> DB
A --> V
DB --> SC --> BR --> HC --> BOT --> PUB
BR --> DEC --> DBKenapa pakai vector index? Karena similarity search penting untuk deduplication dan novelty scoring. Banyak ide yang beda wording tapi sama substansi. Misalnya:
- “How AI agents automate newsletters”
- “Building autonomous content curation agents”
- “AI workflow for daily content ideas”
Secara literal berbeda. Secara semantic, mungkin satu cluster. Kalau tidak ditangani, morning briefing akan terasa repetitive.
Data Model: Jangan Mulai dari Prompt, Mulai dari Schema
Kesalahan umum dalam AI automation: orang langsung mulai dari prompt. Padahal sistem yang stabil mulai dari data model.
Untuk content pipeline, minimal kita butuh schema seperti ini:
CREATE TABLE content_ideas (
id UUID PRIMARY KEY,
source_type TEXT NOT NULL,
source_url TEXT,
source_author TEXT,
raw_text TEXT NOT NULL,
normalized_title TEXT,
summary TEXT,
tags TEXT[],
entities TEXT[],
language TEXT,
detected_topic TEXT,
relevance_score NUMERIC DEFAULT 0,
engagement_score NUMERIC DEFAULT 0,
novelty_score NUMERIC DEFAULT 0,
feasibility_score NUMERIC DEFAULT 0,
freshness_score NUMERIC DEFAULT 0,
final_score NUMERIC DEFAULT 0,
presented_count INTEGER DEFAULT 0,
selected_count INTEGER DEFAULT 0,
rejected_count INTEGER DEFAULT 0,
status TEXT DEFAULT 'candidate',
created_at TIMESTAMPTZ DEFAULT now(),
last_seen_at TIMESTAMPTZ DEFAULT now(),
last_presented_at TIMESTAMPTZ,
selected_at TIMESTAMPTZ,
decay_factor NUMERIC DEFAULT 1.0
);
Field pentingnya bukan cuma title dan URL. Yang bikin pipeline pintar adalah metadata:
- presented_count untuk tahu item sudah berapa kali muncul
- selected_count untuk learning dari preferensi manusia
- rejected_count untuk menurunkan item yang sering ditolak
- decay_factor untuk mengurangi score setelah tampil
- novelty_score untuk menghindari topik yang sudah terlalu sering muncul
- feasibility_score untuk membedakan ide menarik vs ide yang bisa dieksekusi
Kalau Anda membangun ini untuk banyak blog atau brand, tambahkan table channels dan channel_fit_score. Satu ide bisa cocok untuk blog engineering, tapi tidak cocok untuk LinkedIn executive update. Satu ide bisa bagus untuk GitHub tutorial, tapi terlalu teknis untuk newsletter umum.
Contoh tambahan:
CREATE TABLE content_channels (
id UUID PRIMARY KEY,
name TEXT NOT NULL,
type TEXT NOT NULL,
audience TEXT,
tone TEXT,
owner_bot TEXT,
publishing_rules JSONB
);
CREATE TABLE idea_channel_scores (
idea_id UUID REFERENCES content_ideas(id),
channel_id UUID REFERENCES content_channels(id),
fit_score NUMERIC NOT NULL,
reason TEXT,
PRIMARY KEY (idea_id, channel_id)
);
Dengan ini, morning briefing bisa bilang bukan cuma “ini ide bagus”, tapi juga “ini cocok untuk blog A, GitHub repo B, dan LinkedIn thread C”.
Phase 1: Scraping Multi-Source
Scraping jangan dipahami sebagai “ambil semua yang bisa diambil”. Itu barbar. Better approach: buat connectors yang purpose-driven.
Sumber bisa dibagi menjadi beberapa kategori:
1. Social Signals
Social media memberi sinyal engagement dan trend velocity. Dari sini kita bisa mengambil:
- Post dengan likes/comments tinggi
- Thread yang viral di niche tertentu
- Pertanyaan yang sering muncul
- Opinion yang memicu diskusi
- Pain point yang disebut berulang
Yang perlu disimpan bukan cuma text. Simpan juga engagement metadata.
@dataclass
class SocialItem:
source: str
url: str
author: str
text: str
likes: int
comments: int
shares: int
published_at: datetime
scraped_at: datetime
2. Website and RSS
RSS masih underrated. Untuk blog engineering, RSS adalah sumber yang relatif bersih karena sudah berupa artikel. Kita bisa ambil:
- Title
- Summary
- URL
- Published date
- Author
- Tags
Pseudocode:
import feedparser
from datetime import datetime
def scrape_rss(feed_url: str) -> list[dict]:
feed = feedparser.parse(feed_url)
items = []
for entry in feed.entries:
items.append({
"source_type": "rss",
"source_url": entry.link,
"source_author": getattr(entry, "author", None),
"raw_text": f"{entry.title}\n\n{getattr(entry, 'summary', '')}",
"published_at": getattr(entry, "published", None),
"scraped_at": datetime.utcnow().isoformat(),
})
return items
3. GitHub Signals
Untuk audience developer, GitHub adalah content goldmine. Tapi jangan cuma ambil trending repo. Ambil juga:
- New releases dari projects yang relevan
- Issues yang banyak comment
- PR yang memperkenalkan pattern baru
- README yang menjelaskan architecture menarik
- Stars velocity
Contoh connector:
import requests
def search_github_repos(query: str, token: str) -> list[dict]:
response = requests.get(
"https://api.github.com/search/repositories",
headers={"Authorization": f"Bearer {token}"},
params={
"q": query,
"sort": "stars",
"order": "desc",
"per_page": 20,
},
timeout=20,
)
response.raise_for_status()
ideas = []
for repo in response.json()["items"]:
ideas.append({
"source_type": "github",
"source_url": repo["html_url"],
"source_author": repo["owner"]["login"],
"raw_text": f"{repo['full_name']}\n{repo.get('description') or ''}",
"metadata": {
"stars": repo["stargazers_count"],
"forks": repo["forks_count"],
"language": repo["language"],
"updated_at": repo["updated_at"],
},
})
return ideas
4. Internal Notes and Conversations
Ini sering paling valuable. Banyak content bagus lahir dari pertanyaan real customer atau problem internal. Kalau ada WhatsApp/Telegram/Slack summary, meeting notes, atau incident report, semuanya bisa masuk pipeline.
Tapi hati-hati: privacy dan confidentiality. Jangan asal masukkan data sensitif ke pipeline publik. Saya biasanya pakai rule:
- Strip nama orang/perusahaan jika tidak perlu
- Mask phone/email/API keys
- Flag internal-only ideas
- Human approval wajib sebelum publish
Architecture-wise, internal notes bisa masuk sebagai source type internal_note, lalu diberi constraint lebih ketat.
Phase 2: Normalization and Deduplication
Setelah scraping, semua source punya format berbeda. Normalizer bertugas membuat semuanya menjadi bentuk content_idea.
Normalization melakukan beberapa hal:
- Clean whitespace dan HTML
- Remove tracking parameters dari URL
- Extract title jika memungkinkan
- Detect language
- Generate short summary
- Assign preliminary tags
Pseudocode:
from urllib.parse import urlparse, urlunparse, parse_qsl, urlencode
TRACKING_PARAMS = {"utm_source", "utm_medium", "utm_campaign", "utm_term", "utm_content"}
def clean_url(url: str) -> str:
parsed = urlparse(url)
query = [(k, v) for k, v in parse_qsl(parsed.query) if k not in TRACKING_PARAMS]
return urlunparse(parsed._replace(query=urlencode(query)))
def normalize_item(item: dict) -> dict:
raw_text = " ".join(item["raw_text"].split())
return {
"source_type": item["source_type"],
"source_url": clean_url(item.get("source_url", "")),
"source_author": item.get("source_author"),
"raw_text": raw_text,
"metadata": item.get("metadata", {}),
}
Deduplication sebaiknya dua lapis:
- Exact dedupe berdasarkan canonical URL atau hash text.
- Semantic dedupe berdasarkan embedding similarity.
Exact dedupe gampang:
import hashlib
def content_hash(text: str) -> str:
normalized = " ".join(text.lower().split())
return hashlib.sha256(normalized.encode()).hexdigest()
Semantic dedupe lebih menarik. Kita generate embedding untuk summary/raw text, lalu cek apakah sudah ada item mirip di vector index.
def is_semantic_duplicate(embedding, vector_index, threshold=0.88) -> bool:
nearest = vector_index.search(embedding, top_k=3)
return any(match.score >= threshold for match in nearest)
Kalau duplicate, jangan langsung buang. Update last_seen_at dan mungkin tambah source baru. Ide yang muncul dari banyak sumber bisa berarti sinyalnya kuat.
def upsert_idea(candidate):
existing = find_by_url_or_hash(candidate)
if existing:
existing.last_seen_at = now()
existing.metadata["source_count"] = existing.metadata.get("source_count", 1) + 1
save(existing)
return existing
similar = find_semantic_match(candidate)
if similar:
similar.last_seen_at = now()
similar.metadata.setdefault("related_sources", []).append(candidate["source_url"])
save(similar)
return similar
return insert_new(candidate)
Ini penting karena pipeline yang baik bukan cuma mengumpulkan, tapi juga mengerti bahwa internet sering mengulang hal yang sama dengan bungkus berbeda.
Phase 3: AI Enrichment
Setelah item masuk database, enrichment agent bertugas memahami isi. Ini tempat AI agent mulai berguna.
Untuk setiap ide, agent bisa menghasilkan:
normalized_titlesummarydetected_topictagsentitiescontent_anglesrisk_notespossible_outputs
Contoh prompt enrichment:
ENRICHMENT_PROMPT = """
You are a content strategy analyst for an engineering and AI blog.
Analyze the following scraped item.
Return JSON with:
- normalized_title: concise title
- summary: 2 sentence summary
- tags: 3-7 tags
- detected_topic: main topic
- content_angles: 3 possible blog angles
- possible_outputs: blog_post, github_repo, linkedin_post, newsletter, short_video
- risk_notes: privacy, factual uncertainty, legal, or none
Item:
{raw_text}
Source: {source_url}
"""
Output-nya harus structured JSON. Jangan biarkan model jawab bebas. Kalau bebas, downstream system menderita.
{
"normalized_title": "Building AI Agents for Content Curation",
"summary": "The item discusses using agents to collect and rank content ideas. It is relevant for teams trying to automate editorial workflows without removing human judgment.",
"tags": ["ai-agents", "automation", "content-strategy", "workflow"],
"detected_topic": "AI content automation",
"content_angles": [
"How to design a scoring engine for content ideas",
"Why human curation still matters in AI publishing",
"Building a morning briefing agent for creators"
],
"possible_outputs": ["blog_post", "linkedin_post", "github_repo"],
"risk_notes": "none"
}
Enrichment juga bisa menilai audience fit. Misalnya untuk blog engineering, item terlalu marketing-heavy bisa tetap disimpan, tapi score relevansinya rendah.
Phase 4: Scoring Algorithm
Scoring adalah jantung pipeline. Kalau scoring jelek, morning briefing akan terasa random. Kalau scoring bagus, manusia merasa “wah, ini sistem ngerti gue”.
Saya suka memecah final score menjadi beberapa komponen:
final_score =
0.30 * relevance_score +
0.20 * engagement_score +
0.20 * novelty_score +
0.15 * feasibility_score +
0.10 * freshness_score +
0.05 * strategic_fit_score
Bobot ini bukan sakral. Untuk blog teknis, relevance dan feasibility mungkin lebih penting daripada engagement. Untuk social media growth, engagement bisa dinaikkan.
Relevance Score
Relevance menilai apakah ide cocok dengan domain kita. Untuk blog engineering dan AI automation, topik seperti agent orchestration, Python automation, infrastructure, DevOps, data pipeline, dan applied AI akan tinggi.
Pseudocode:
CORE_TOPICS = {
"ai agents": 1.0,
"automation": 0.95,
"python": 0.85,
"devops": 0.8,
"content strategy": 0.75,
"engineering management": 0.7,
}
def score_relevance(tags: list[str], detected_topic: str) -> float:
score = 0.0
for tag in tags:
score = max(score, CORE_TOPICS.get(tag.lower(), 0.0))
topic_score = CORE_TOPICS.get(detected_topic.lower(), 0.0)
return max(score, topic_score)
Dalam production, saya lebih suka gabungkan rules dengan LLM judge. Rules memberi consistency, LLM memberi nuance.
def llm_relevance_judge(idea, editorial_profile) -> float:
prompt = f"""
Rate relevance from 0 to 1 for this editorial profile.
Editorial profile:
{editorial_profile}
Idea:
{idea.summary}
Return only a number between 0 and 1.
"""
return float(call_llm(prompt))
Engagement Score
Engagement score berasal dari social metrics dan trend velocity. Tapi hati-hati: viral bukan berarti valuable.
import math
def score_engagement(metadata: dict) -> float:
likes = metadata.get("likes", 0)
comments = metadata.get("comments", 0)
shares = metadata.get("shares", 0)
stars = metadata.get("stars", 0)
raw = likes + (2 * comments) + (3 * shares) + (0.5 * stars)
return min(1.0, math.log1p(raw) / 10)
Log scale penting supaya satu viral post tidak menghancurkan scoring lain.
Novelty Score
Novelty mengecek apakah topik ini baru dibanding ide yang sudah pernah muncul atau sudah pernah dipublish.
def score_novelty(idea_embedding, published_index, candidate_index) -> float:
published_similarity = published_index.max_similarity(idea_embedding)
recent_candidate_similarity = candidate_index.max_similarity(idea_embedding, days=14)
similarity = max(published_similarity, recent_candidate_similarity)
return max(0.0, 1.0 - similarity)
Kalau similarity 0.9 dengan artikel yang baru publish minggu lalu, novelty score harus rendah. Bukan berarti idenya buruk. Artinya bukan prioritas pagi ini.
Feasibility Score
Ini bagian yang sering dilupakan. Ada ide yang kelihatan bagus tapi butuh data yang tidak kita punya, akses yang sulit, atau waktu riset panjang. Feasibility menilai apakah ide bisa dieksekusi dalam waktu reasonable.
Contoh heuristic:
- Ada source jelas: +0.2
- Butuh eksperimen coding yang bisa dilakukan: +0.2
- Butuh proprietary data: -0.3
- Topik terlalu broad: -0.2
- Bisa jadi tutorial praktis: +0.3
def score_feasibility(idea) -> float:
score = 0.5
if idea.source_url:
score += 0.15
if "tutorial" in idea.tags or "python" in idea.tags:
score += 0.2
if "requires private data" in idea.risk_notes:
score -= 0.3
if len(idea.summary.split()) < 20:
score -= 0.1
if "possible_outputs" in idea.metadata and "github_repo" in idea.metadata["possible_outputs"]:
score += 0.1
return max(0.0, min(1.0, score))
Freshness Score
Freshness adalah age-based score. Ide baru dapat boost. Ide lama turun perlahan.
from datetime import datetime, timezone
def score_freshness(created_at: datetime) -> float:
age_hours = (datetime.now(timezone.utc) - created_at).total_seconds() / 3600
if age_hours < 24:
return 1.0
if age_hours < 72:
return 0.8
if age_hours < 168:
return 0.5
return 0.2
Strategic Fit Score
Strategic fit mengikuti arah blog atau bisnis. Misalnya bulan ini fokus pada AI agents, OpenClaw, dan automation. Ide di area itu dapat boost.
CURRENT_FOCUS = ["ai agents", "openclaw", "automation", "agent workflow"]
def score_strategic_fit(idea) -> float:
text = f"{idea.normalized_title} {idea.summary} {' '.join(idea.tags)}".lower()
matches = sum(1 for focus in CURRENT_FOCUS if focus in text)
return min(1.0, matches / 2)
Akhirnya:
def compute_final_score(idea) -> float:
base = (
0.30 * idea.relevance_score +
0.20 * idea.engagement_score +
0.20 * idea.novelty_score +
0.15 * idea.feasibility_score +
0.10 * idea.freshness_score +
0.05 * idea.strategic_fit_score
)
return base * idea.decay_factor
Simple, explainable, tunable. Itu lebih baik daripada black-box score yang tidak bisa didebug.
Phase 5: Morning Briefing System
Morning briefing adalah interface utama antara machine curation dan human judgment. Kalau briefing-nya jelek, seluruh pipeline terasa tidak berguna.
Briefing harus singkat, actionable, dan punya context. Jangan cuma list title. Minimal tampilkan:
- Rank
- Title
- Score
- Why it matters
- Suggested output
- Effort estimate
- Risk note
- Source link
Contoh format:
Top 10 Content Ideas - 08:00 WITA
1. AI agents for content curation
Score: 0.87
Why: Strong fit with current AI automation focus, good tutorial potential.
Output: Blog post + GitHub repo
Effort: Medium
Risk: None
Source: https://example.com/thread
2. Postgres vector search for editorial workflows
Score: 0.82
Why: Practical engineering angle, can be turned into code-heavy tutorial.
Output: Technical blog
Effort: Medium
Risk: Needs benchmark validation
Pseudocode scheduler:
from datetime import datetime
def generate_morning_briefing(db, limit=10):
ideas = db.query("""
SELECT * FROM content_ideas
WHERE status = 'candidate'
AND final_score > 0.35
ORDER BY final_score DESC
LIMIT %s
""", [limit])
briefing = []
for rank, idea in enumerate(ideas, start=1):
briefing.append({
"rank": rank,
"title": idea.normalized_title,
"score": round(idea.final_score, 2),
"why": explain_score(idea),
"suggested_outputs": idea.metadata.get("possible_outputs", []),
"effort": estimate_effort(idea),
"risk": idea.risk_notes,
"source": idea.source_url,
})
mark_as_presented(ideas)
return briefing
explain_score penting. Humans trust systems better when systems explain themselves.
def explain_score(idea) -> str:
reasons = []
if idea.relevance_score > 0.8:
reasons.append("high relevance to current editorial focus")
if idea.engagement_score > 0.7:
reasons.append("strong engagement signal")
if idea.novelty_score > 0.7:
reasons.append("fresh angle compared to recent posts")
if idea.feasibility_score > 0.7:
reasons.append("practical to produce quickly")
return ", ".join(reasons) or "balanced score across multiple signals"
Delivery channel bisa Telegram, email, dashboard, atau internal app. Untuk saya, Telegram-style briefing paling enak karena bisa cepat dipilih dengan reply atau button.
Show diagram source
sequenceDiagram
participant Cron
participant DB
participant Scorer
participant BriefingBot
participant Human
participant ProducerBot
Cron->>Scorer: Run daily scoring at 07:30
Scorer->>DB: Update final_score
Cron->>BriefingBot: Generate top 10 at 08:00
BriefingBot->>DB: Fetch ranked candidates
BriefingBot->>Human: Send morning briefing
Human->>BriefingBot: Pick item 1, 4, 7
BriefingBot->>ProducerBot: Create content jobs
ProducerBot->>DB: Update selected statusPhase 6: Human Curation Workflow
Ini bagian yang menurut saya paling penting secara filosofi: human stays in the loop.
AI bisa mengumpulkan dan mengurutkan, tapi manusia tetap menentukan:
- Apakah ide ini cocok dengan arah bisnis?
- Apakah timing-nya pas?
- Apakah ada data yang cukup?
- Apakah topik ini sensitif?
- Apakah output-nya harus blog, repo, atau social post?
Workflow idealnya tidak ribet. Human cukup memilih action:
Approve as blog postApprove as GitHub tutorialApprove as LinkedIn postSave for laterRejectMerge with another idea
Di backend, action ini menjadi feedback signal.
def handle_human_action(idea_id: str, action: str, notes: str | None = None):
idea = db.get_idea(idea_id)
if action == "approve_blog":
idea.status = "selected"
idea.selected_count += 1
idea.selected_at = now()
create_content_job(idea, channel="blog")
elif action == "approve_github":
idea.status = "selected"
idea.selected_count += 1
create_content_job(idea, channel="github")
elif action == "save_later":
idea.status = "backlog"
idea.decay_factor *= 0.85
elif action == "reject":
idea.rejected_count += 1
idea.status = "rejected" if idea.rejected_count >= 2 else "candidate"
idea.decay_factor *= 0.5
elif action == "merge":
merge_idea_cluster(idea_id, notes)
db.save(idea)
Human notes juga valuable. Kalau owner bilang “ini bagus tapi terlalu broad, fokus ke Python implementation”, note itu harus ikut ke production bot.
Phase 7: Content Production Delegation
Setelah ide dipilih, jangan langsung satu generic AI menulis semua. Better pattern: tiap blog/channel punya managing bot dengan personality, rules, dan quality gate masing-masing.
Misalnya:
- Blog engineering bot: long-form technical writing, code snippets, diagrams
- GitHub tutorial bot: repo scaffold, README, runnable examples
- LinkedIn bot: short opinionated post, executive tone
- Newsletter bot: curated summary, concise, link-heavy
- Video bot: script, storyboard, caption plan
Content job bisa punya schema seperti ini:
CREATE TABLE content_jobs (
id UUID PRIMARY KEY,
idea_id UUID REFERENCES content_ideas(id),
channel_id UUID REFERENCES content_channels(id),
assigned_bot TEXT NOT NULL,
status TEXT DEFAULT 'queued',
human_notes TEXT,
draft_url TEXT,
quality_score NUMERIC,
created_at TIMESTAMPTZ DEFAULT now(),
completed_at TIMESTAMPTZ
);
Ketika owner approve ide untuk blog, job dibuat:
def create_content_job(idea, channel: str):
channel_config = db.get_channel(channel)
job = {
"idea_id": idea.id,
"channel_id": channel_config.id,
"assigned_bot": channel_config.owner_bot,
"status": "queued",
"human_notes": idea.metadata.get("human_notes"),
}
db.insert("content_jobs", job)
notify_bot(channel_config.owner_bot, build_assignment_prompt(idea, channel_config))
Assignment prompt harus membawa context lengkap:
def build_assignment_prompt(idea, channel):
return f"""
You are the managing bot for {channel.name}.
Create content based on this selected idea.
Title: {idea.normalized_title}
Summary: {idea.summary}
Source: {idea.source_url}
Tags: {idea.tags}
Human notes: {idea.metadata.get('human_notes', 'none')}
Channel rules:
Audience: {channel.audience}
Tone: {channel.tone}
Publishing rules: {channel.publishing_rules}
Requirements:
- Produce a draft, not final publish
- Include factual source references
- Flag uncertainty
- Return status and draft location
"""
Ini membuat pipeline modular. Discovery system tidak perlu tahu detail cara menulis blog. Blog bot yang tahu.
Phase 8: Score Decay Mechanism
Score decay adalah mekanisme kecil yang efeknya besar. Tanpa decay, ide yang score-nya tinggi akan muncul terus setiap pagi sampai manusia bosan.
Aturan dasarnya:
- Setiap kali item muncul di morning briefing, decay factor turun.
- Kalau dipilih, status berubah jadi selected dan tidak muncul lagi sebagai candidate.
- Kalau ditolak, score turun lebih agresif.
- Kalau source baru muncul untuk ide yang sama, score bisa naik lagi.
- Setelah periode tertentu, item bisa recover sedikit jika masih relevan.
Contoh:
def mark_as_presented(ideas):
for idea in ideas:
idea.presented_count += 1
idea.last_presented_at = now()
idea.decay_factor *= 0.72
idea.final_score = compute_final_score(idea)
db.save(idea)
Kenapa 0.72? Tidak sakral. Ini berarti item yang muncul sekali akan turun 28%. Kalau masih sangat kuat, mungkin besok masih muncul. Kalau biasa saja, dia hilang dari top 10.
Untuk rejected item:
def reject_idea(idea):
idea.rejected_count += 1
idea.decay_factor *= 0.45
if idea.rejected_count >= 2:
idea.status = "rejected"
db.save(idea)
Untuk recovery:
def recover_old_candidates():
candidates = db.query("""
SELECT * FROM content_ideas
WHERE status = 'candidate'
AND last_presented_at < now() - interval '14 days'
AND decay_factor < 1.0
""")
for idea in candidates:
idea.decay_factor = min(1.0, idea.decay_factor + 0.08)
idea.final_score = compute_final_score(idea)
db.save(idea)
Decay membuat suggestion tetap fresh tanpa membuang knowledge lama.
Feedback Loop: Sistem Harus Belajar dari Pilihan Manusia
Kalau owner sering memilih ide dengan tags python, openclaw, dan ai-agents, scoring harus pelan-pelan menaikkan bobot area itu. Kalau ide dengan tags web3 selalu ditolak, jangan terus muncul.
Simple learning bisa dibuat tanpa ML rumit:
def update_topic_preferences():
selected = db.query("SELECT tags FROM content_ideas WHERE selected_count > 0")
rejected = db.query("SELECT tags FROM content_ideas WHERE rejected_count > 0")
weights = defaultdict(float)
for row in selected:
for tag in row.tags:
weights[tag] += 0.05
for row in rejected:
for tag in row.tags:
weights[tag] -= 0.03
for tag, delta in weights.items():
db.adjust_topic_weight(tag, delta, min_value=0.2, max_value=1.5)
Dengan cara ini, sistem makin lama makin personal. Bukan karena prompt makin panjang, tapi karena feedback loop-nya rapi.
Quality Gates Before Publishing
Saya anti full autopublish untuk konten yang membawa nama bisnis atau personal brand. AI boleh produce draft, tapi sebelum publish harus ada gate.
Minimal quality gate:
- Fact check source utama
- Link validation
- No duplicate image
- No hallucinated company/customer names
- Code snippets reviewed atau marked pseudocode
- Tone sesuai channel
- SEO title dan description masuk akal
- Human approval untuk final publish
Untuk technical blog, tambahkan:
- Code runnable jika diklaim runnable
- Mermaid diagram valid
- No exposed secrets
- No private internal data
- No claims without source atau disclaimer
Pseudocode gate:
def run_quality_gate(draft):
checks = [
validate_links(draft),
detect_secrets(draft),
check_duplicate_images(draft),
verify_mermaid_blocks(draft),
check_required_frontmatter(draft),
llm_tone_review(draft),
]
failed = [check for check in checks if not check.passed]
if failed:
return {
"status": "needs_revision",
"failed_checks": failed,
}
return {"status": "ready_for_human_review"}
Ini bukan birokrasi. Ini safety belt. Konten yang salah bisa merusak trust lebih cepat daripada konten bagus membangunnya.
Deployment Pattern: Start Small, Then Scale
Kalau Anda ingin membangun pipeline ini, jangan langsung 20 sumber dan 8 bots. Start small.
Versi MVP cukup:
- RSS scraper untuk 10 sumber
- GitHub scanner untuk 5 query
- Postgres database
- Simple LLM enrichment
- Rule-based scoring
- Telegram/email morning briefing
- Manual approve/reject
- Score decay
Setelah itu baru tambah:
- Social media connectors
- Vector dedupe
- Channel-specific scoring
- Production bots
- Dashboard
- Learning from feedback
- Automated quality gate
MVP architecture:
Show diagram source
flowchart LR
RSS[RSS Feeds] --> PY[Python Ingestion Script]
GH[GitHub Search] --> PY
PY --> DB[(Postgres)]
DB --> AI[LLM Enrichment]
AI --> SCORE[Scoring]
SCORE --> TG[Telegram Morning Briefing]
TG --> HUMAN[Human Picks]
HUMAN --> BOT[Blog Bot Draft]Ini bisa dibangun dalam beberapa hari. Yang penting schema dan workflow-nya benar.
Example End-to-End Run
Bayangkan sistem berjalan jam 06:30.
Scraper menemukan beberapa items:
- GitHub repo baru tentang browser automation agents
- Blog post tentang vector search untuk knowledge base
- Thread tentang AI content workflows
- Internal note tentang ide “morning briefing agent”
- Release notes framework Python baru
Normalizer membersihkan URL dan text. Deduper melihat thread AI content workflows mirip dengan internal note, lalu menggabungkannya sebagai related sources. Enrichment agent memberi title: “Building a Morning Briefing Agent for Content Ideas”.
Scoring engine menghitung:
- Relevance: 0.95 karena cocok dengan AI automation
- Engagement: 0.72 karena thread ramai
- Novelty: 0.81 karena belum pernah ditulis
- Feasibility: 0.88 karena bisa dibuat tutorial
- Freshness: 1.00 karena baru
- Strategic fit: 0.90 karena sesuai focus bulan ini
Final score setelah decay factor 1.0: 0.87.
Jam 08:00, item masuk top 10. Owner memilih “approve as blog post” dan memberi note: “Bikin practical, include scoring formula dan score decay”. Blog bot menerima job, membuat outline, menulis draft, menambahkan code snippets dan Mermaid diagram. Quality gate mengecek link, image, frontmatter, dan secrets. Draft masuk human review.
Setelah item tampil di briefing, presented_count naik dan decay factor turun. Karena item dipilih, status berubah selected, jadi tidak muncul lagi sebagai candidate. Kalau source lain muncul besok tentang tema yang sama, deduper tahu bahwa cluster ini sudah selected dan hanya bisa muncul sebagai follow-up angle, bukan ide yang sama.
That is the difference between random AI automation and actual editorial operating system.
Results You Should Expect
Pipeline seperti ini biasanya memberi hasil di beberapa area:
1. Ide Lebih Konsisten
Tidak ada lagi hari blank. Setiap pagi ada top 10. Tidak semuanya akan bagus, tapi selalu ada bahan untuk dipilih.
2. Curation Lebih Cepat
Human tidak mulai dari internet kosong. Human mulai dari shortlist yang sudah diberi context, score, dan suggested output.
3. Produksi Lebih Terarah
Bot produksi tidak menerima prompt vague seperti “tulis tentang AI”. Mereka menerima idea object dengan source, summary, reason, angle, dan channel rules.
4. Repetition Turun
Score decay dan semantic dedupe mengurangi ide yang muter-muter. Ini bikin briefing terasa fresh.
5. Knowledge Base Makin Kaya
Setiap scraped item, selected item, rejected item, dan published output menjadi data. Lama-lama sistem bukan cuma pipeline konten, tapi editorial memory.
Lessons Learned
Ada beberapa lesson yang menurut saya penting.
Pertama, AI agent paling berguna ketika diberi workflow yang jelas. Kalau agent cuma disuruh “carikan ide bagus”, hasilnya random. Kalau agent diberi schema, scoring dimensions, dan feedback loop, hasilnya jauh lebih stabil.
Kedua, human curation bukan kelemahan. Banyak orang terlalu terobsesi dengan full automation. Untuk content yang punya brand voice, judgment manusia itu feature, bukan bottleneck. Yang perlu diotomasi adalah kerja repetitif sebelum keputusan.
Ketiga, scoring harus explainable. Kalau sistem tidak bisa menjelaskan kenapa satu ide ranking #1, manusia akan sulit percaya. Simple weighted score yang bisa dijelaskan sering lebih baik daripada ML model opaque.
Keempat, decay is underrated. Tanpa decay, sistem akan annoying. Dengan decay, sistem terasa hidup. Item lama mundur, item baru naik, tapi knowledge lama tidak hilang.
Kelima, quality gate wajib. AI-generated draft tanpa gate itu seperti deploy tanpa test. Kadang lolos, kadang meledak. Untuk personal brand dan bisnis, jangan main-main.
Practical Implementation Checklist
Kalau mau build minggu ini, ini checklist yang paling realistis:
- Tentukan 10-20 source awal
- Buat
content_ideastable - Tulis RSS/GitHub scraper sederhana
- Tambahkan exact dedupe by URL/hash
- Tambahkan LLM enrichment JSON
- Implement scoring formula explainable
- Generate top 10 briefing harian
- Tambahkan approve/reject/save action
- Implement score decay setelah presented
- Buat production job queue untuk selected ideas
- Tambahkan quality gate sebelum publish
- Review feedback tiap minggu dan adjust bobot
Jangan tunggu sempurna. Pipeline yang sederhana tapi jalan setiap hari lebih valuable daripada arsitektur megah yang tidak pernah dipakai.
Closing: Build an Editorial Operating System, Not a Content Gimmick
AI-powered content pipeline bukan tentang mengganti penulis. Bukan juga tentang memproduksi artikel sebanyak mungkin sampai internet tambah penuh sampah.
Buat saya, ini tentang membangun editorial operating system.
Sistem yang menangkap sinyal dari internet, menyaring yang relevan, memberi prioritas, mengingat apa yang sudah pernah muncul, belajar dari pilihan manusia, lalu mengarahkan agent produksi dengan context yang cukup.
Mesin melakukan heavy lifting. Manusia menjaga taste.
Dan kombinasi itu jauh lebih kuat daripada keduanya berjalan sendiri-sendiri.
Kalau tim Anda punya banyak ide tapi sering kehilangan momentum, mulai dari pipeline kecil: scrape, store, score, brief, curate, delegate, decay. Itu saja dulu. Setelah rhythm-nya terbentuk, baru scale sources, bots, dan channels.
Karena content strategy yang bagus bukan cuma soal kreativitas. It is also about throughput, feedback loops, and system design.
Dan di era AI agents, tim yang menang bukan yang paling banyak prompt-nya. Tim yang menang adalah yang punya pipeline paling rapi.
← Artikel Sebelumnya
Personal AI Use Case: Subscription Hunter
Artikel Selanjutnya →
AI Agent Buat Daily Work Harus Punya Repair Harness
Baca Juga


Ada Pertanyaan? Yuk Ngobrol!
Butuh bantuan setup OpenClaw, konsultasi IT, atau mau diskusi project engineering? Book a call langsung — gratis.
Book a Call — Gratisvia Cal.com • WITA (UTC+8)
Newsletter
Subscribe to Newsletter
Artikel baru, automation notes, dan engineering insight. Clean inbox, no spam.
Dengan subscribe, kamu setuju menerima update seperlunya.